Auditory Stream Segregation


Introduction
If you were in the room listening to the quintet at left, sounds from the bass, saxophone, guitar, trumpet, and drums would all enter your auditory system through the same pair of auditory canals. Yet you would hear five distinct streams of sounds, one coming from each instrument.
The process of dividing your auditory world up into separate sound-emitting objects is called auditory stream segregation. Some of the means by which we segregate streams are fairly obvious. For example, we can safely assume that sounds coming from different spatial locations (see the activity on Auditory Localization Cues) are coming from different sources.
However, you would still hear five distinct instruments even if you listened to a monaural recording of our quintet, so spatial location can’t be the only hint we use to segregate streams. In fact, we have a whole host of principles for grouping sounds into streams, just as we have a host of Gestalt principles for grouping visual stimuli into objects.
In this activity, we’ll explore one of these principles, grouping by frequency, using a series of simple tone sequences.
Instructions
Click on the “Demonstration, Part 1” link to begin the activity.
Demonstration, Part 1
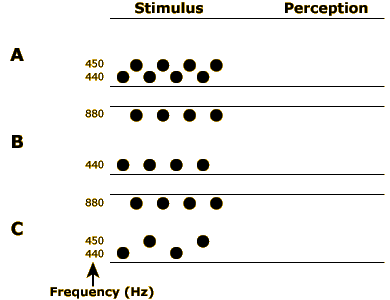
This part of the demonstration includes three sequences of sounds, which you can play by clicking the speakers at left or the links in the text.
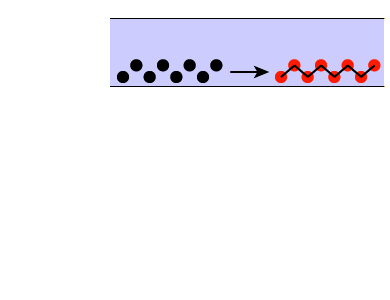
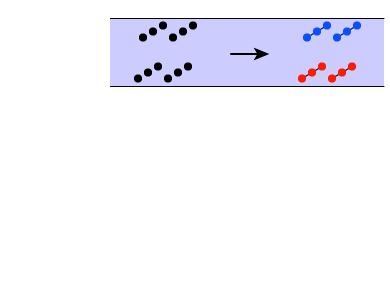
The first two sequences are really just two tones, one lower-frequency tone and one higher-frequency tone, endlessly repeating. In sequence A, the lower-frequency tone has a frequency of 440 Hz and the higher-frequency tone is just a bit higher, 450 Hz. Each tone is 100 milliseconds (ms) long, and the tones are separated by gaps of 10 ms. When you play this sequence, you should hear the two tones “warbling” back and forth, as indicated in the diagram at far right.
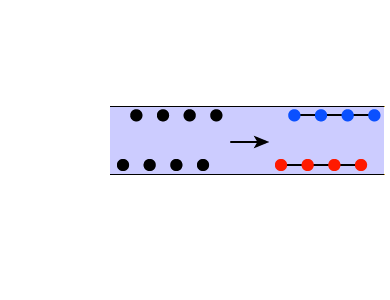
In sequence B, the lower-frequency tone is again 440 Hz, but this time the higher-frequency tone is a full octave higher, 880 Hz. The lengths of the tones and gaps is identical to sequence A, but when you play this sequence, you will probably not hear these two tones as alternating back and forth. Instead, you will probably hear what is diagrammed at far right—one stream of repeating high tones superimposed on a separate stream of repeating low tones.
What’s happening here? In sequence A, the two tones were close enough together in frequency that your auditory system grouped the tones into a single stream. But in sequence B, the tones are farther apart in frequency, so you concluded that there were two separate auditory objects and created two separate streams: one for the high tones and one for the low tones.
Now look at the tone diagram for sequence C. How many streams do you think your auditory system will detect here? Play the sequence and find out, then move on to the second part of the demonstration.
Demonstration, Part 2
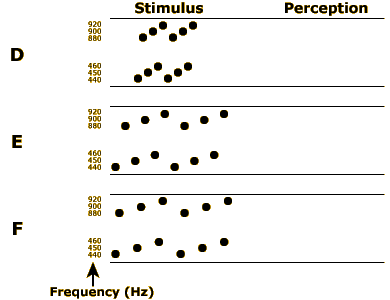
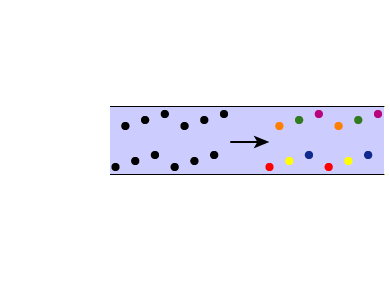
Tone sequence D picks up where sequence C from the previous part left off. Play this sequence and you should hear two separate streams: one for the three lower-frequency tones rising from 440 Hz to 450 Hz and another for the three higher-frequency tones rising from 880 Hz to 900 Hz to 920 Hz.
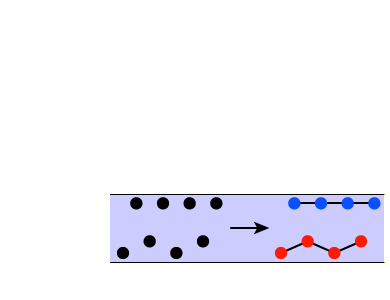
Now try tone sequence E. This sequence includes exactly the same frequencies, in the same order, as sequence D. The only difference is that the interval between the tones has been increased from 10 ms to 400 ms. This should sound much less like two separate streams. Instead, you should perceive one stream of alternating low and high tones. Or, you may not combine any of the tones into streams at all—you might just perceive each tone as a separate auditory object.
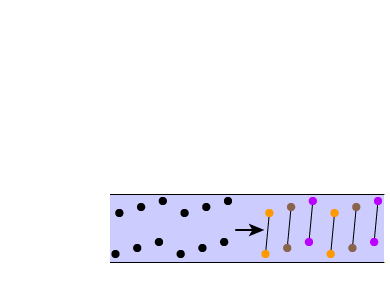
Finally, listen to tone sequence F. Here, some of the inter-note intervals have been cut down to 10 ms again. As a result, you should now perceive three distinct groups of tones, each composed of one low and one high tone.
In this last sequence, it would appear that we’ve discovered another stream segregation principle, which we might call grouping by time—sounds that are heard close to each other in time tend to group together. Moreover, we see that in this case, the grouping by time principle overpowers the grouping by frequency principle. Just as was the case for the Chapter 4, the auditory stream segregation principles presented in this chapter should be treated as aids that help us understand the overall stream segregation process but there are no simple, hard-and-fast stream segregation “laws.”