Chapter 4 Study Questions
What and Where Pathways
1. What cortical brain structures does visual information pass through as it is processed?
Answer: Information first reaches the cortex in a region called striate cortex, so-called because it has a distinctive striped pattern under the microscope. Early vision processes are carried out here. Then information is passed to extrastriate cortex, where the tasks of middle vision are carried out (for example, this is where illusory contours are processed). From there, information travels via two separate pathways, one that ends in the parietal lobe, and one that terminates in inferotemporal (IT; lower temporal lobe) cortex. It is in IT cortex that the end-stage processing of face and object recognition is carried out.
2. What are the receptive field characteristics of cells in inferotemporal (IT) cortex?
Answer: Many neurons in IT have been shown to respond most actively to particular objects or faces. The term “grandmother cell” was coined to describe these neurons, the implication being that a single cell might be ultimately responsible for deciding whether an image was of one’s grandmother’s face. In support of the grandmother cell hypothesis, recordings of single cells in the IT of humans have identified cells that only respond to the actress Jennifer Aniston.
3. What methods are used to study the function of brain areas such as IT?
Answer: Some labs lesion (surgically remove) parts of the brains in nonhuman subjects to see what functions are impaired following the surgery. The results of such studies are often compared to deficits shown by human patients who have had homologous regions of their brains damaged by accident. Other labs use single-cell recording techniques to determine the responses of individual neurons to different types of stimuli (it was in these labs that grandmother cells were found). Recently, many labs have started employing noninvasive techniques such as functional magnetic resonance imaging (fMRI), which can take snapshots of neural activity in humans’ brains as they perform different tasks.
The Problems of Perceiving and Recognizing Objects
4. What are some of the major challenges when recognizing objects?
Answer: One challenge is how to recognize objects regardless of the viewpoint you happen to see them in. The retinal images of an object from multiple viewpoints might be quite different, yet we still need to recognize all of those images as coming from the same object. A second challenge is how to separate out the contours of objects from the background and from other objects that might be in front of them.
5. What does the term “middle vision” refer to?
Answer: Middle vision is a loosely defined stage of visual processing that comes after basic features have been extracted from the image (low-level, or early vision) and before object recognition and scene understanding occur (high-level vision).
Middle Vision
6. Why can’t we apply a simple rule like “homogeneous areas belong to the same object” in order to find an object’s contours?
Answer: Because humans sometimes perceive object contours even in areas of an image where there is no physical difference between the object and its background (see Figure 4.10).
7. Draw a figure that includes an illusory contour.
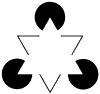
Answer: An illusory contour is one that is perceived even though they are not present in the physical stimulus. The Kanisza triangle (left) is one famous example; another illusory contour is shown below.
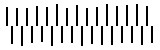
8. What is the guiding philosophy behind Gestalt psychology? How does it contrast with the earlier approach known as structuralism?
Answer: The structuralists believed that perception of a complex scene was simply the sum of the basic “atoms” of perception (color, orientation, etc.) in the scene. Gestalt psychologists reacted to this position, arguing that a perceptual whole was much more than the sum of its elemental parts.
9. What do the Gestalt grouping rules seek to describe?
Answer: The grouping rules describe which elements in an image will appear to group together.
10. Why is it important to include the phrase “all else being equal” when stating the Gestalt grouping principles?

Answer: Because we can only be absolutely sure that a principle will adequately predict how elements will be grouped if no other principles can also be applied. For example, at right we see a display in which the proximity grouping principle would suggest that we organize the elements into four columns, while the similarity principle suggests we should perceive five rows. Only one principle can “win” (in this case, most people probably see rows rather than columns).
11. How are the Gestalt grouping principles related to texture segmentation?
Answer: A texture is really just a collection of many perceptual elements that are similar to each other and arranged closely together. Therefore, stating that areas of an image with different textures are segmented from each other (the definition of texture segmentation) is really the same thing as saying that areas of an image in which elements are similar to each other and/or close together group together.
12. How is camouflage related to grouping principles?
Answer: To camouflage yourself, you have to make your features (that is, the visual elements that are visible to anyone who might observe you) group with the features present in your environment.
13. What is the basic idea behind the “perception by committee” metaphor?
Answer: The visual world is a complicated place, and no one rule for interpreting the world can possibly do an adequate job. But once we introduce multiple rules, conflicts between interpretations will inevitably arise. Various parts of our visual system act like perceptual committees, considering which rules conflict and which agree in a given situation and eventually arriving at a single interpretation for the scene.
14. What are ambiguous figures, and how do they relate to the perception by committee metaphor?
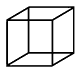
Answer: Ambiguous figures, such as the Necker cube seen at left, have more than one valid interpretation. Our perceptual committees settle on one and only one of these interpretations at a time, but the interpretation may “flip” from time to time.
15. What are some of the assumptions that perceptual committees make?
Answer: First, the committees must “know” something about physics; for example, understanding that opaque objects block light is a prerequisite for perceiving the illusory edges of the triangle in the Kanisza triangle. Second, the committees assume that we are not viewing a scene from an accidental viewpoint, which would mask the true structure of the objects in the scene.
16. What is figure–ground assignment?
Answer: The process of determining that some regions of an image belong to the foreground object (figure) and other regions are part of the background (ground).
17. What is the notion of relatability and why is it important?
Answer: Relatability is the notion that line segments on either side of an occluding surface will look like they are part of a single object if they can be connected by a smooth curve that only bends once. This concept is important because it describes the constraints our brains use to fill in edge information from objects that is missing due to occlusion.
18. What do nonaccidental features tell us about a scene?
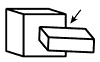
Answer: Certain arrangements of edges can be interpreted as providing important information about segmenting objects in a scene, provided we are seeing the edges from a nonaccidental viewpoint. For example, a “T-junction” (a place where one edge abuts another straight edge in a T-like fashion; the arrow in the figure at left points to a T-junction) strongly indicates that the two edges are parts of different objects.
19. What rules do our perceptual committees use to divide objects into parts?

Answer: One widely accepted proposal is that we use valleys, rather than bumps, in an object as clues to where to divide the object into parts, cutting the object by connecting pairs of valleys (see figure at left).
20. What evidence is there that the visual system starts with large objects and then divides them into smaller parts, rather than processing scenes the other way around?
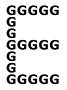
Answer: Evidence for this proposition comes from the global superiority effect. In displays like those at the left, it was found that identifying the small (local) letters took longer than identifying the larger (global) letter, indicating that the global information is more readily available than the local information. That is, in the figure at left, you tend to see the E before the Gs.
Object Recognition
21. What is the fundamental goal of object recognition?
Answer: To match a perceived stimulus to a representation of a previously encountered object encoded in memory.
22. What is a naive template theory, and why can such theories be rejected as a complete theory of object recognition?
Answer: The formal definition of a template is complicated, but template theories essentially follow a “lock and key” principle. The perceived image is the key, and the template is the lock. The naive template approach says that we store templates for all the images of all the objects we have ever seen. When we perceive an object that we want to recognize, we try to match this perception to all the templates stored in memory until we find a lock in which the key fits exactly. This doesn’t strike most people as being a very efficient process. One of the most important problems is that it seems unlikely that we have enough brain capacity to store templates to match every single object in every single viewpoint that we are likely to encounter in our lives.
23. What is the basic idea behind a structural description, and how do structural description theories improve on template theories?
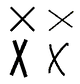
Answer: A structural description describes the structure of an object in terms of its constituent parts and the relationships between those parts. The advantage over templates is that a single structural description can potentially match a large number of slightly different shapes. For example, if an X is described as two oblique lines that cross near their centers, this description will match all the figures at left. However, each figure would require a different template in a naive template theory.
24. What is a geon?
Answer: Geons are “geometric ions” and are the three-dimensional building blocks of structural descriptions in Biederman’s recognition-by-components theory of object recognition. The defining quality of geons is that they are discriminable from each other based on non-accidental features, so they should be easily recognizable from any viewpoint.
25. Describe the essence of the viewpoint invariance versus viewpoint dependence debate in the object recognition literature.
Answer: Many structural description theories, such as recognition-by-components, predict that in most circumstances, object recognition should be equally efficient (i.e., equally fast) regardless of whatever viewpoint you see the object from. Such a pattern of performance, in which recognition time does not vary across changes in viewpoints, is known as viewpoint invariance. However, many empirical studies have revealed that object recognition times are in fact dependent on viewpoint. If subjects study a novel object from a single viewpoint, they are usually slower at recognizing the object later when shown from a new viewpoint than when shown from the trained viewpoint.
26. What do we mean when we say that objects can be recognized at different levels?
Answer: Object recognition is essentially a categorization process. Identifying an object means deciding what category the object belongs in. Most objects actually have a number of categories that they could be placed in. The level of recognition refers to the specificity of the category you use when identifying an object. For instance, you can recognize a chair as a “barber chair,” “chair,” or “furniture,” depending on what category you are using.
27. What are basic, subordinate, and superordinate categories?
Answer: These terms are best described in relation to each other. A subordinate level category is one that is quite specific, referring to a relatively small number of objects (e.g., Camaro). A superordinate level category, on the other hand, is much more general. Superordinate categories are often defined by functional or conceptual, rather than shape-based, qualities (e.g., vehicle). Basic level categories are in-between (e.g., car).
28. Why is face recognition thought to be accomplished via different mechanisms than object recognition?
Answer: Most objects require considerably more time to recognize at the subordinate than at the basic level. However, recognition of individual faces, which is a subordinate-level task, is a very fast process—so fast that many researchers believe the visual system must use “special” mechanisms to recognize faces. Also, face recognition and object recognition can be doubly dissociated—people with object agnosia can recognize faces but not objects whereas people with prosopagnosia can recognize objects but not faces.
29. What is the face inversion effect, and how does it relate to the special mechanisms thought to be operating when we recognize faces?
Answer: Faces are more difficult than other objects to recognize when inverted. Researchers have proposed that when faces are inverted, the special processes that are usually brought to bear in recognizing faces cannot operate, so we are forced to rely on our “normal” object recognition processes, which are not as efficient for subordinate-level objects, like faces.
30. What is prosopagnosia, and what does it say about special face recognition processes?
Answer: Prosopagnosia is a neuropsychological disorder in which people cannot recognize faces, although they can recognize other objects normally. It is due to damage in fusiform face area (FFA) of the brain where special face recognition processes are carried out.